
Keeping Flowglad/skills automatically up to date
Recently, we launched our first set of agent skills at flowglad/skills.
flowglad/skills allows your coding agents to access skills helpful for integrating Flowglad into your codebase. They help AI coding assistants properly set up Flowglad, configure subscriptions, handle checkout sessions, and more. You can add these skills to your codebase by running npx skills add flowglad/skills through Vercel's new skills.sh—it's phenomenally quick and easy for users. Unfortunately, it requires maintaining a separate GitHub repository flowglad/skills.
The problem: Keeping a separate repo up to date
The separate repository requirement creates a maintenance burden. Every time we want to update a skill, we'd need to remember to push changes to both our main monorepo and the standalone flowglad/skills repository. It's easy to forget, and it's annoying to maintain state in two places. But more importantly, it breaks the workflow that makes our monorepo so powerful.
At Flowglad, we use a monorepo pattern for a variety of reasons. One important benefit in the age of code gen agents is that they have easy access to the whole system, which greatly aids their understanding. When an AI agent is working in our monorepo, it can see the actual implementation code, the documentation, the tests, and the skills all in one place. This context is invaluable. The agent can understand not just what the API does, but how it's implemented, and how everything fits together.
To get the benefits of the monorepo—ease of access to edit the skills, relevant context from the rest of the codebase, etc. we set up a GitHub Action that automatically pushes changes from the skills directory in our monorepo directly to the flowglad/skills GitHub repo on push to main.
The workflow watches for changes in the skills/** path and, when it detects updates, it clones the target repository, replaces its contents with our monorepo's skills directory, and commits the changes. This keeps the two repositories in sync automatically, so we never have to think about updating a separate repo manually. This is great. But what happens if the skills themselves are no longer up to date because the product has changed?
The deeper problem: Preventing documentation drift
Skills are essentially just another medium for product documentation. As product docs, skills come with a nontrivial maintenance burden: you have to keep them substantively up to date with your product. This is true of all product docs. By publishing a skill, you are increasing the surface area of docs you need to maintain. And by consequence, proportionately increasing the potential for documentation drift. In order to deliver the best experience possible for developers building with AI, documentation drift is non-negotiable. It's exactly the kind of subtle problem that will drag a human back into the loop. Solving it isn't just eliminating a chore, but building a key piece of infrastructure to ensure we can keep moving at warpspeed without worry about drift.
We realized that by formalizing the relationship between docs and skills, we could eliminate the possibility of documentation drift at the skill level. First, for each skill we list its docs “dependencies”. We also record when it was last reviewed. We encode this metadata at the top of each skill page in HTML comments. Here's what the metadata looks like:
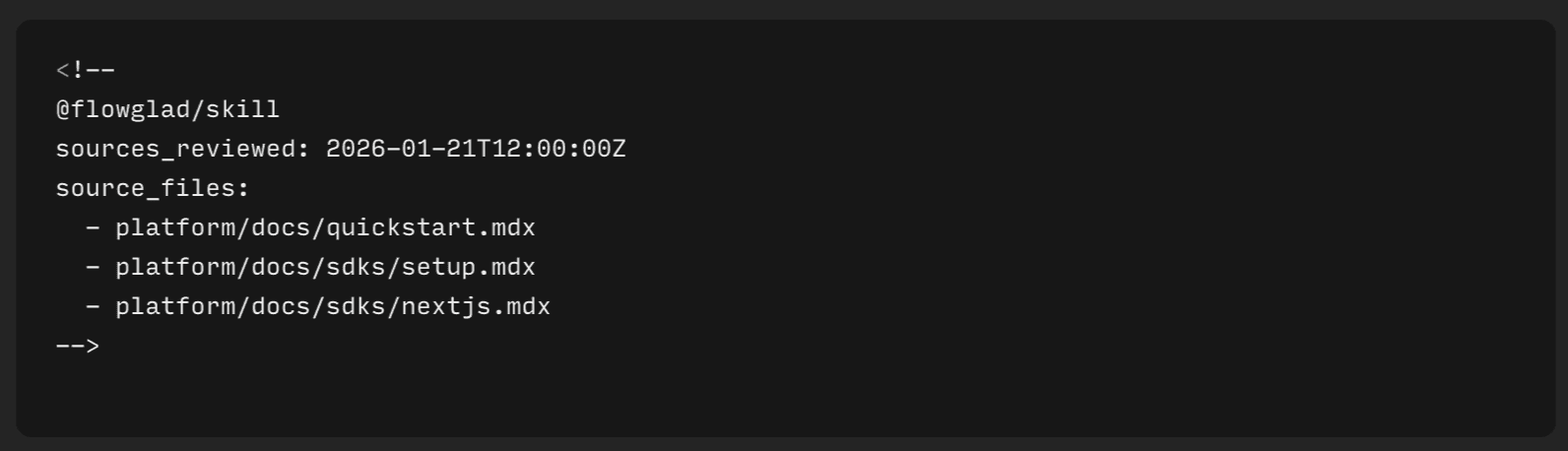
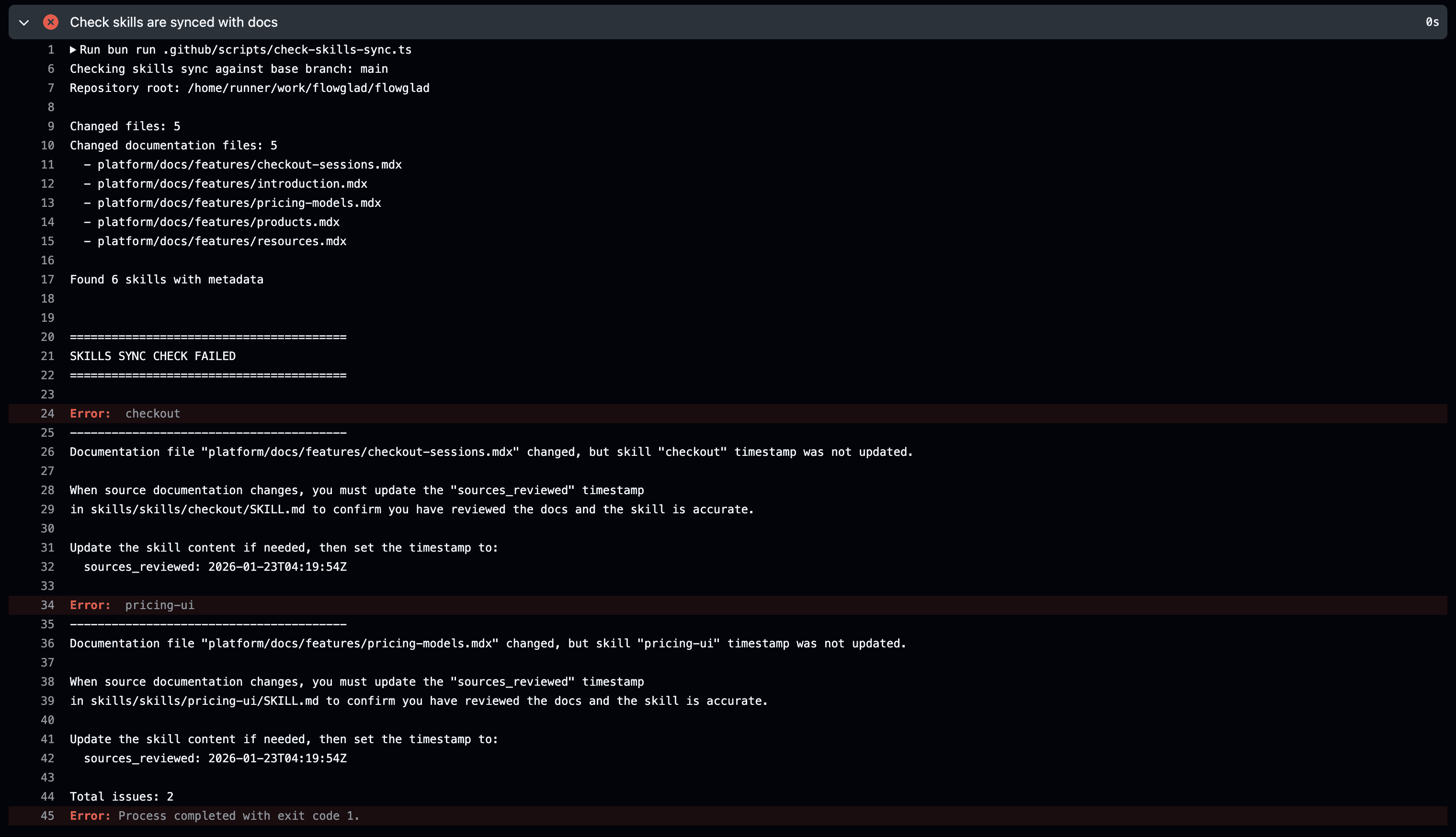
This enables us to make skills drift something we can check for deterministically. We have a CI that runs on every pull request that touches either documentation files or skill files. It scans all the skills in our skills/skills/ directory and checks if any of their source documentation has changed. If the docs dependencies have been updated more recently than the skills, we throw an error in CI, blocking the merge.
The CI script parses this metadata, compares the current branch's documentation files against the base branch, and checks if any of the listed source files have changed. If they have, it then checks whether the sources_reviewed timestamp in the skill file has been updated to a time later than the original timestamp. If not, the check fails with a clear error message telling the developer exactly which skill needs updating and what timestamp to use.
This ensures that when documentation changes, someone has explicitly verified that the corresponding skill is still accurate. It's not enough to just update the docs, you also have to consciously review the skill and confirm it's still correct.
This semantic verification step is crucial because skills often contain nuanced guidance, examples, and gotchas that might not be obvious from just reading the documentation. The timestamp serves as proof that a human (or agent) reviewed the skill in the context of the updated documentation.
The full result is that we get skills based on our product docs, published in their own dedicated repo, that is automatically kept up to date with our latest documentation. And with this approach, we can expand the skills we publish substantially without exploding our maintenance burden or accruing a larger surface area for drift.
1
/** Make internet money with Flowglad */